텐서플로우에서 CNN 구조를 정의하는 기초 예제를 정리해둔다. (MNIST 데이터 셋을 사용한다고 했을 경우.) (1) Placeholder 정의 : (2) Filter weight 정의 (3) 레이어 정의 (3-1) 인풋 텐서 / weight 텐서를 conv 레이어의 파라미터로 지정. 여기서 padding = 'SAME'은 convolution 이후의 필터당 아웃풋의 이미지 사이즈가 인풋 이미지의 사이즈와 같도록… Continue reading Implementing CNN in Tensorflow
Category: DL Basics
Implementing RNN in Tensorflow
예전 프로젝트에서는 RNN 구현에 있어서 Keras를 사용해서 (example코드를 거의 그대로 사용) 별 고민 없이 쉽게 해결했었다. 물론 cs231n의 숙제로 RNN을 numpy로 쩔쩔매며 구현하기도 했었지만, 실제 프로젝트에서 자주 쓰기 위해서는 역시 Tensorflow 레벨에서의 활용방법을 간단히 정리해놓는 것이 필요하다고 판단. 텐서플로우에서 RNN을 사용하는 방식은 다음과 같다. Cell을 정의한다. (BasicLSTMCell 등의 구현된 클래스 사용. 내부에 연산한 후 output값과… Continue reading Implementing RNN in Tensorflow
Cross-entropy/softmax 정리
_cross-entropy cost function Big picture in a nutshell (svm & cross-entropy loss) : 주의해서 봐야할 점은 weight matrix인데, 각 레이블에 대응하는 weight가 따로따로 있다. (그러므로 feature 갯수 by label class 갯수인 테이블이 된다.) 이 말은 각 샘플마다 (x0, x1, x2) 자기에게 맞는 클래스가 있을텐데 이를 제외한 클래스를 향하는 weight 값을 사용해서 얻은 loss를… Continue reading Cross-entropy/softmax 정리
Understanding of Backpropagation
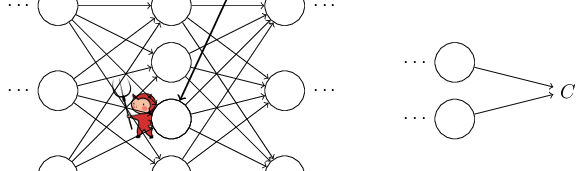
에버노트에 정리한 링크 : Backpropagation Note (개념적으로 훌륭히 정리되어 있는 글을 번역했다.)
Linear classification – image classification
cs231n은 참 명강의이다. 처음 딥러닝을 이 강의로 접했다. linear classification을 보면서 맨처음 접했던 Andrew Ng 교수님 초보 머신러닝 강의(코세라)와 개념 이어붙이느라 고생했다. 그 때 정리했던 노트를 올려본다. cs231n module1 - Linear classification Image Classification assigning a single label to an image KNN classifier by comparing them to images from training set (this causes space problem,… Continue reading Linear classification – image classification
Softmax 정리
Softmax SVM과 더불어 많이 쓰이는 Classifier. Logistic regression classifier의 multiple class 에 대한 일반화 개념. 각 class의 score를 받아서 normalized class probability들을 리턴한다. Score를 unnormalized log probabilies for each class로 해석한다. Hinge loss(SVM애서의)를 cross-entropy loss로 대체한다. (두식은 같은 식 : i class의 loss) 여기서 fj가 j번째 클래스의 score Softmax function : (여기에… Continue reading Softmax 정리
Batch normalization memo
Batch normalization 발표를 위해 메모. prerequisite _ Loss는 mini-batch의 모든 sample들의 영향을 한꺼번에 받아서 결정된다. _ covariate shift는 train data 와 test data 의 input data distribution이 다른 현상을 의미한다. 이 경우, Loss function(통계학적으로 보면 하나의 ‘가설'이라 할 수 있다.)결과값에서 data batch의 다른 특성에 의한 차이가 있을 수 있기 때문에 문제가 발생한다. 이것이 뉴럴넷의… Continue reading Batch normalization memo
Nuts and Bolts of Applying Deep Learning (Andrew Ng)
푸근한 앤드류 응 교수님의 세션. 큰 그림과 실제 연구에서의 팁 등을 포함하고 있는 좋은 세션. 간단히 메모. https://www.youtube.com/watch?v=F1ka6a13S9I DL. why r they working so well ? amount of data traditional learning algorithms general dl sequential model image model unsupervised / reinforcement learning #2 end-to-end dl movie review -> sentiment 0/1 image -> object recognition 1~1000… Continue reading Nuts and Bolts of Applying Deep Learning (Andrew Ng)
