Image-to-image Translation with Conditional Adversarial Networks 논문 정리 : https://arxiv.org/abs/1611.07004
목적: Conditional adversarial network를 image-to-image translation의 general-purpose solution으로 사용해보는 것.
- input image ⇒ output image의 맵핑
- 이 맵핑을 train하는데 필요한 loss function 자체를 학습
이 모델은
- label map에서 photo synthesis
- edge map에서 object reconstruct
- colorizing image
문제들에 효과적이었음을 보였다.
Mapping function을 더이상 hand-engineer하지 않고, loss function도 hand-engineer하지 않았음에도 reasonable한 결과를 얻어냈다.
Language translation 문제처럼 image-to-image translation을 접근했다. 즉, 많은 데이터를 통해서 한 이미지의 representation 을 다른 이미지로 변환하는 방식을 배우도록 하는 것.
Language translation에서 어려운 점은, 한 언어에서 표현하는 개념이 다른 언어에서 표현하기 어려운 경우이다. 마찬가지로, 이미지 translation에서도 (many-to-one:computer vision문제 – 사진에서 edge, segment, semantic label을 찾아내는 문제 / one-to-many:computer graphics문제 – label이나 sparse user input을 이미지로 변환하는 문제) 이런 어려움이 있다.
전통적으로는 이런 문제들을 특정 machinery로 해결해왔다. 우리는 (다양한 문제에 대해) 이것을 통틀어서 해결하는 framework를 제시하고 싶었다.
_이를 위해 CNN을 사용한 방법들이 많이 제시되어왔다. 하지만 loss function을 우리가 잘 정의해주어야 했다.
Naive approach를 보자면, Euclidean distance를 (predicted랑 ground truth 사이) loss로 설정하면 blurry한 image를 결과로 얻게 된다. (plausible한 아웃풋들을 averaging하는 방식이기 때문에)
⇒ Loss function을 잘 정의해서 sharp하고 realistic한 이미지를 만들어내도록 하는 것이 하나의 연구분야이며, expert domain knowledge를 요구하는 분야이다.
_하지만! 그냥 high-level에서의 목표만을 던져주고 (‘realistic한 이미지를 만들어!’ 같은..) 자동으로 loss function 자체를 학습하도록 하는 건 어떨까?
이런 접근이 최근의 GAN 모델들에서 구현되었다.
- GAN (오리지널)
- Deep generative image models using a laplacian pyramid of adversarial networks
- Unsupervised representation learning with deep convolutional generative adversarial networks (DCGAN)
- Improved techniques for training GANs, T.Salimans et al., 2016
- Energy-based generative adversarial network, J. Zhao et al., 2016
GAN은 blurry한 이미지를 용인하지 않고, realistic한 이미지를 생성하도록 학습된다.
이 논문에서는 conditional setting에서의 GAN 모델을 토대로 연구해보려 한다. (cGAN) Input image에 컨디션을 주어서 원하는 output image를 얻어내는 방식이다.
GAN연구는 엄청 많이 되었지만 개별 주제에 대한 연구가 많았고, img2img 문제에 대한 general-purpose solution으로 GAN이 어떻게 효과적인지 명확하게 설명되지 않았기 때문에, 이 연구를 하게 되었다.
논문에서 보이려는 것 :
- 다양한 문제에 대해서 conditional GAN이 reasonable한 결과를 보여준다는 것.
- 좋은 결과를 낼 수 있는 단순한 framwork를 만들고, 이 구조의 주요 부분들에 대해서 왜 효과적인지를 밝혀내는 것.
(저자는 코드도 공개함.)
https://github.com/phillipi/pix2pix
1_ 관련 연구
- Structured losses for image modelling
- Img2img 문제는 픽셀 단위의 classification/regression로 여겨져 옴.
- 이런 접근은 output space를 ‘unstructured’하다고 여김. (각 output pixel들은 서로간에는 독립.)
- 반면 Conditional GAN은 이와 달리 structured loss를 학습 : output 픽셀들의 joint configuration을 penalize.
- SSIM metric
- feature matching
- nonparametric losses
- convolutional pseudo-prior
- matching covariance statistics 기반의 loss
: 우리의 cGAN은 output과 target 사이의 어떤 possible한 structure 차이도 다 penalize할 수 있다는 점에서 이와 다르다.
- Conditional GAN : 우리가 Conditional한 세팅의 GAN 모델을 처음 사용한 건 아니다.
- discrete한 label condition을 사용하는 문제들 :
- text condition
- image condition
- impainting
- image production from a normal map
- image manipulation guided by user constraints
- future frame prediction
- future state prediction
- product photo generation
- style transfer
- 이런 모델들은 본인의 특정 분야에 적용되었다. -> 우리 framework는 application-specific하지 않게 디자인하려 한다.
- 또한, 아키텍쳐 측면에서도, 우리는 generator에 U-Net 구조를 사용하고, discriminator로 convolutional PatchGAN classifier구조를(image patch 크기에서만 제한하여 penalize) 사용했다. : Precomputed real-time texture synthesis with markovian generative adversarial networks ⇒ 로컬한 style statistics를 capture하기 위한 구조
- discrete한 label condition을 사용하는 문제들 :
2_ Method
Conditional GAN
- x : observed image
- z : random noise vector
- y : output image
⇒ {x와 z} 와 y 사이의 맵핑(G)을 학습.
G: {x, z} →y
G는 실제 이미지와 구분이 안가는 output을 만들도록 학습, discriminator D는 fake와 원본을 구분하도록 학습.
2_1 Objective
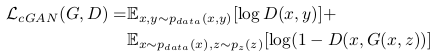
G tries to minimize / D tries to maximize (mini-max problem)
Discriminator에 대한 컨디셔닝의 중요성을 테스트하기 위해서, 우리는 unconditioned variant와 비교하였다. (Discriminator가 x를 observe하지 않도록 / G는 그대로 observe)
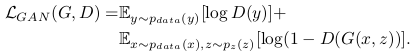
기존 연구들에서, GAN objective와 전통적인 loss(L2 같은..)를 섞으면 conditional GAN이 좀 더 잘 작동한다는 것을 알아냈다.
⇒ 이 때 Discriminator가 하는 일은 변함이 없지만, generator는 discriminator를 속이는 일 뿐 아니라 ground truth와의 L2 distance를 줄이는 일을 동시에 하게 된다. 우리는 추가로, L1을 쓰는게 덜 blurry하다는 것도 발견했음.
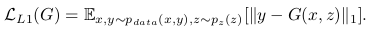
⇒ 따라서, 최종 objective는 다음과 같음.
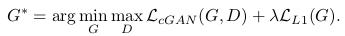
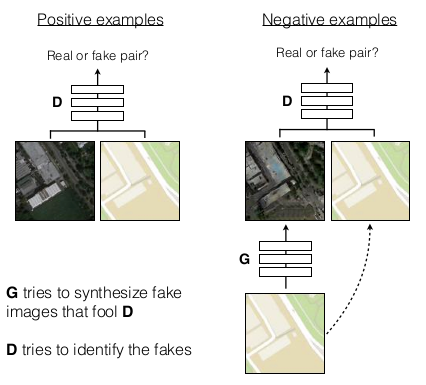
위 그림은 지도 이미지에서 aerial photo를 생성하는 예이다. 일반 GAN과 달리, Conditional GAN은 generator와 discriminator 모두 image를 인풋으로 받도록 되어 있다.
z가 없어도 네트워크는 x에서 y로 가는 맵핑을 학습할 수 있지만, deterministic한 아웃풋을 내어 놓을 것이고, delta function을 학습하게 된다.(우리가 원하는 건 matching distribution..)
기존 conditional GAN도 이 문제를 해결하기 위해 가우시안 노이즈 z를 generator의 인풋에 추가한 것이다.
초기 실험에서는 이 방식이 별로 효과적이지 못햇다. (Generator가 노이즈를 무시하도록 학습되었다..) ‘Deep multi-scale video prediction beyond mean square error’논문에서처럼..
대신에, 그래서 우리 모델에서는 노이즈를 dropout의 형태로만 집어넣었다. Training과 test time 모두 generator의 여러개의 레이어에 이 노이즈를 적용했다.
Dropout 노이즈가 있음에도 불구하고, output에는 매우 마이너한 수준의 stochasticity만이 도출될 뿐이었다.
⇒ 따라서 stochastic한 output을 생성하는 conditional GAN을 디자인하는 것(즉, 모델링되는 conditional distribution들의 full entropy를 모두 반영하는)은, 매우 중요한 문제로 남아 있다.
2_2 Network Architectures
- 기본적으로 DCGAN의 모델을 사용.
- G와 D 모두 Convolution – Batch Norm – ReLU 로 구성된 모듈들을 사용
- Appendix에 자세한 아키텍쳐 기록 (깃헙에 공개) https://github.com/phillipi/pix2pix
2_2_1 Generator with Skips
- map a high resolution input grid ⇒ a high resolution output grid
- input과 output의 surface appearance가 다르지만,
- 그 둘의 underlying structure는 같다.
⇒ input의 structure가 output의 structure와 roughly aligned되어 있다.
Encoder-decoder 네트워크 형태로 이 문제에 접근한 연구들 :
- Context encoders: Feature learning by inpainting.
- Generative image modeling using style and structure adversarial networks.
- Perceptual losses for real-time style transfer and super-resolution.
- Learning temporal transformations from time-lapse videos.
- Pixel-level domain transfer.
⇒ input이 레이어들을 통과하며 점차 down sample되고, bottleneck layer에서는 반대 과정으로 디코딩 된다.
이런 모델에서는 모든 정보가 모든 레이어를 따라 전달된다. (bottleneck 레이어 포함)
하지만, 많은 이미지 translation 문제에서, 많은 양의 low-level 정보가 사실 input과 output에 의해 share된다. 그러므로 이 정보들은 directly 전달되도록 하는 것이 좋지 않을까?
(예를 들어 colorizing문제를 보자면 주요 edge정보들은 input과 output이 share하기 때문에 그대로 올려주는 게 낫다.)
이런 shared 정보까지 bottleneck을 통과하지 않도록 하기 위해, 우리는 skip connection을 추가한 U-Net이라는 모델을 구축했다. 레이어 i와 레이어 n-i사이 마다 (n: 전체 레이어 수) skip connection을 추가했는데, 각 skip connection은 모든 채널에서 단순히 벡터를 concatenate하는 방식이다.
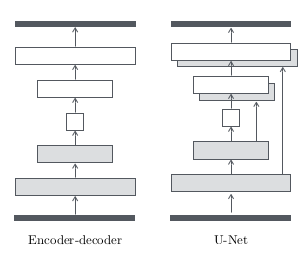
<U-Net 구조>

<Encoder-decoder 모델 / U-Net 모델 결과 비교>
2_2_2 Markovian discriminator (PatchGAN)
L2 loss는 blurry한 결과물을 내어주지만, 여전히 low frequency를 정확히 잡아준다는 이점이 있다.
이 장점을 살리기 위해 L1 loss를 사용했다.
즉, GAN discriminator를 제한해서 high-frequency structure만을 모델링하도록 하고, L1 term으로 하여금 low-frequency의 정확도를 높이도록 구성해보았다.
- High-frequency structure를 모델링하기 위해서는 local image patch에만 집중하도록 하면 된다. 따라서 PatchGAN이라는 discriminator 아키텍쳐를 디자인했다. (patch 크기에서만 structure를 penalize하는 구조)
- 즉, N x N 크기의 각 patch들이 real인지 fake인지를 판단하는 discriminator를 학습하는 것.
- 이 discriminator를 이미지 전체에 convolve시켜서 loss를 average한 것이 최종 output이 됨.
- N이 아주 작아져도 여전히 높은 퀄리티의 결과물을 내어주었다. (patch가 작을 수록 parameter수가 적어지니까 퍼포먼스가 좋아지고, 더 큰 이미지에 적용이 가능하다.
⇒ 재미있는 것은.. 이런 discriminator는 이미지를 하나의 MRF(Markov random field: 다시보자 PGM..)로 모델링해준다. (patch의 직경보다 더 멀리 있는 pixel들은 서로 independent하다는 가정하에)
- Precomputed real-time texture synthesis with markovian generative adversarial networks.
- Texture synthesis by non-parametric sampling
- Image quilting for texture synthesis and transfer.
- Image style transfer using convolutional neural networks.
- Combining markov random fields and convolutional neural networks for image synthesis.
(위 논문들에서 이런 관계를 발견했다. )
2_3 Optimization and Inference
오리지널 GAN논문의 standard한 optimization 방식을 따랐다.
- D에 대해 gradient decent step 한번 ⇒ G에 대해 gradient decent step 한번
- minibatch SGD
- Adam solver
Inference 때는 training때와 똑같은 방식으로 generator 네트워크를 작동시켰다.
- 일반적으로는 training때는 dropout을 적용하고 test때는 빼버리지만, 우리는 test때도 dropout을 적용했다.
- 또한, test time때 test batch의 statistics를 사용한 batch normalization도 사용했다. (일반적으로는 training batch의 statistics의 합을 사용함.) ⇒ 이런 방식은 만약 batch size를 1로 설정하면 instance normalization이라고 명명되었다. Instance normalization: The missing ingredient for fast stylization 논문 참고. (이미지 생성 문제에서 효과적이었음.)
- batch size는 문제에 따라 1 또는 4를 사용했다.
3_ Experiments
- Semantic labels↔photo, trained on the Cityscapes dataset
- Architectural labels→photo, trained on the CMP Facades dataset
- Map↔aerial photo, trained on data scraped from Google Maps.
- BW→color photos, trained on Imagenet large scale visual recognition challenge.
- Edges→photo, trained on data from ‘Generative visual manipulation on the natural image manifold.’ and ‘Fine-Grained Visual Comparisons with Local Learning.’ ; binary edges generated using the HED edge detector plus post-processing.
- Sketch→photo: tests edges→photo models on human-drawn sketches from ‘How do humans sketch objects?’
- Day→night, trained on ‘Transient attributes for high-level understanding and editing of outdoor scenes.’
자세한 결과는 논문 참고.
3_1 Evaluation metric
역시 논문 참고.
- AMT perceptual studies
- FCN-score
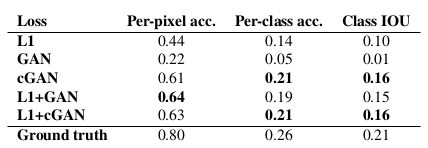
: 각기 다른 loss에 따른 FCN-score표 (Cityscapes labels ↔photo 문제 적용)
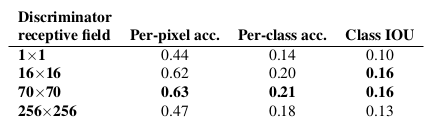
: Discriminator에서의 각기 다른 receptive field size에 따른 FCN-score표(Cityscapes labels ↔photo 문제 적용)
3_2 Analysis of the objective function
이 objective function에서 어떤 부분들이 중요할까?
- L1 term의 효과와 GAN term의 효과를 분리해보기.
- Discriminator를 input에 condition 시켰을 때와 안시켰을 때 비교해보기.

<각 loss의 종류에 따른 결과 비교>
L1 하나만 사용했을 경우 blurry하게 생성되었다. cGAN 하나만 사용했을 경우에는 훨씬 샤프한 이미지를 만들긴 했짐나, 외관을 만드는 데 있어서 artifact들이 있었다. 이 두가지 term을 모두 사용했을 경우에 가장 좋은 결과를 얻을 수 있었다.
Cityscape label ⇒ photo 변환 문제에 있어서 정량평가를 위해 FCN-score를 사용했다.
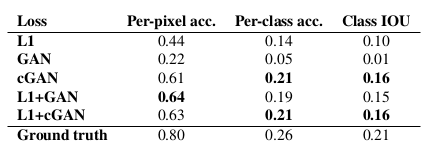
<Cityscape label ⇒ photo 변환 문제 FCN-score 표>
- 전반적으로 보면 cGAN이 GAN보다, 그리고 L1과의 combination이 더 좋은 결과를 내어줌.
- D에 Conditioning이 없는, 즉 D가 x를 보지 않는 모델(GAN이라 표기/G에는 있음)은 사실 인풋과 아웃풋의 mismatch를 따지는 모델이 아니기 때문에 이 metric에서는 안좋은 성능일 수 밖에 없음. (: 참고로 cGAN은 D, G모두 x를 인풋으로 받는 네트워크)
- L1을 사용한다는 것 ⇒ Discriminator가 하는 일은 변함이 없지만, G는 D를 속이는 일 뿐 아니라 ground truth와의 L1 distance를 줄이는 일을 동시에 하게 된다.
L1 / cGAN 두 부분의 역할을 좀더 명확히 해보자면,
- cGAN은 (특정) input과 비슷한 (특정) output을 생성하도록 지도받는다.
- L1 loss는 ground truth와 생성된 output이 서로 비슷해지도록 지도한다.
_Colorfulness
Conditional GAN 모델의 장점은, input label map이 없는 부분에서조차도 spatial한 structure를 만들어 냄으로써 샤프한 이미지를 만들어 생성한다는 것이다.
이런 ‘sharpening’ 효과를 spectral domain에서 갖도록 하는 건 어떨까? 이미지를 좀 더 colorful하게 생생하도록..
L1을 사용하면, edge의 위치가 모호해져서 블러가 생기듯이 color value도 픽셀단위로 정확해지지 않기 때문에 grayish해진다. L1은 가능한 color에 대한 probability density function(conditional)에서 median값을 취하기 때문.
Adversarial loss를 사용하면, 이런 grayish한 color가 unrealistic하다고 판단하기 때문에 실제 color distribution을 따르도록 값들을 수정하게 된다.
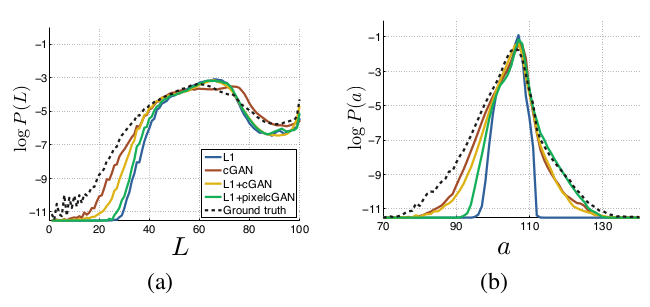
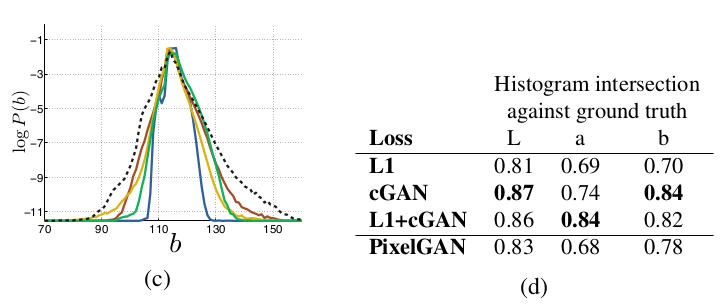
위 표는 cGAN의 color distribution이 ground truth와 얼마나 matching하는지에 대한 표이다. Lab color space에서의 marginal distribution을 비교한 것이다. (Cityscapes 데이터셋)
Ground truth(dotted line)와의 histogram intersection 영역 차이는 높은 probability region에서의 차이 때문에 dominate된다. Log probability를 출력해서 낮은 probability region에서의 차이를 강조했다.
L1 이 더 narrow한 distribution을 보이는데, averaged / grayish color를 만들어내기 때문이다. cGAN이 더 실제에 가까운 color distribution을 보인다고 할 수 있다.
3_3 Anaysis of the generator architecture
U-Net architecture는 low-level 정보가 네트워크를 따라 잘 전달되도록 하기 위함이다. 더 나은 결과를 가져다 주었을까?
<Encoder-decoder 모델 / U-Net 모델 결과 비교>
Encoder-decoder 모델은 U-net 에서 skip-connection들을 잘라내기만 했다. Encoder-decoder 모델은 realistic한 이미지를 만들지 못했고, 각 input label map에 대해 거의 비슷한 결과만을 생성해냈다.
U-Net이 cGAN에서는 어떤 장점을 갖는지 명확하지 않았지만, L1에서는 훨씬 나은 결과를 보여주었다.
3_4 From PixelGANs to PatchGANs to ImageGANs
Discriminator의 receptive field에서의 patch size N을 다양하게 해서 이에 따른 효과를 검증해보았다. (여기서는 모두 L1 + cGAN loss를 사용)

<Patch size에 따른 결과 비교>
- L1에서 uncertain한 region들은 blurry해지고 desaturated된다.
- 1 x 1 PixelGAN은 color diversity가 좋아지도록 하지만 spatial statistics에서는 효과가 없다.
- 16 x 16 PatchGAN은 local하게 sharp한 결과물을 만들지만, 패치의 크기를 벗어나는 부분에 대해서 타일효과 같은 artifact가 나타난다.
- 70 x 70 PatchGAN은 output이 spatial과 spectral(colorfulness) 디멘젼에서 모두 sharp해지도록 했다.(실제와 다르더라도 그럴듯하게)
- 256 x 256 ImageGAN은 70 x 70 PatchGAN과 매우 비슷한 결과물을 만들었지만, FCN-score에서는 왠지 모르게 더 낮은 점수를 얻었다.
_Fully-convolutional translation
PatchGAN의 장점은 fixed-size patch discriminator가 임의의 큰 이미지에도 적용될 수 있다는 점이다. 더 큰 이미지들에 대해서는 generator 또한 convolutional하게 적용할 수 있다.
이런 방식을 map ↔aerial photo task에 실험해보았다. Generator를 256 x 256 이미지에 트레이닝 시킨 후, 512 x 512 이미지에 테스트 해봤다.
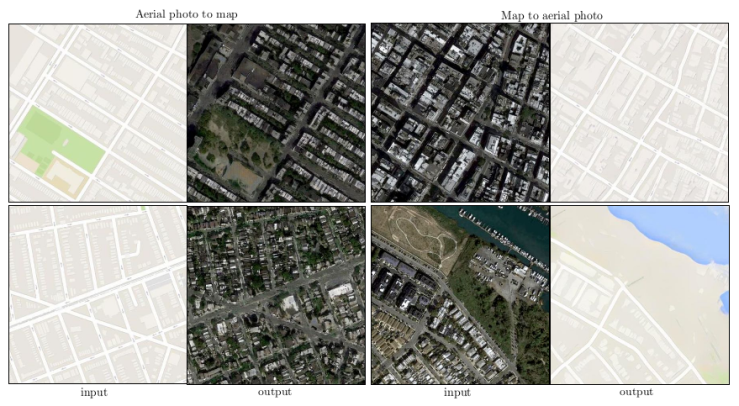
<Example results on Google Maps at 512×512 resolution (model was trained on images at 256×256 resolution, and run convolutionally on the larger images at test time). (Contrast adjusted for clarity.)>
잘 나온다.(..)
3_5 Perceptual validation
- Perceptual realism을 평가해보았다.
- AMT experiment for map↔photo task (몇 퍼센트가 사람들을 실제라고 속일 수 있었는지 평가)

<AMT in “real vs fake” test on maps↔aerial photos.>
Colorization 또한 ImageNet데이터로 학습시켜 보았다. [46]논문의 방식이 더 나은 결과를 보여주긴 했다. (이 문제에 특화된 모델이라서이다..)

<AMT in “real vs fake” test on colorization.>
[46] : Colorful image colorization, R. Zhang et al.
[48] : Learning temporal transformations from time-lapse videos, Y. Zhou et al.

<Colorization results of cGANs vs L2 regression[46] vs full method(classification w/ rebalancing[48]>
cGAN이 좋은 성능을 보여주기도 했지만, gray-scale/saturated한 이미지(마지막 row)에 대해서는 제대로 재현하지 못했다.
3_6 Semantic segmentation
cGAN모델이 highly detailed 이미지나 사진에 대해서 image processing 이나 그래픽스 task들에 대해서는 좋은 성능을 내어주었다.
비전 문제(semantic segmentation)에서는 어떨지도 테스트해보기로 했다. (아웃풋이 인풋에 비해 complex하지 않은..)
Cityscapes→label 문제에 적용해보았다.

<cGAN이 더 sharp한 아웃풋을 내어주었기는 하지만, 존재하지 않는 작은 오브젝트들을 만들어 내었음을 볼 수 있다.>
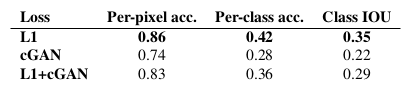
재미있는 것은, cGAN에서 L1 loss를 제거한 경우에도 이 문제에 어느 정도 좋은 정확도를 보여주었다는 사실이다. 우리가 알기로는, 이는 GAN모델이 label을 생성하는 문제에 성공한 첫번째 사례이다. (label을 생성하는 것은 이미지 생성과는 다르게 discrete한 값임에도.)
cGAN이 좋은 퍼포먼스를 내긴 했어도, 이 문제에 대한 best model만큼 좋지는 않았다. (단순히 L1만 사용하는 방법이 오히려 더 나은 결과를 내어줌.) 이는 비전 문제에 있어서는 목표가 더 명확하기 때문에 L1 loss가 충분했기 때문이라고 본다.

<좀 더 많은 example>
더 많은 결과들을 보려면 다음 링크를 참고 :
https://phillipi.github.io/pix2pix/
4_ Conclusion
Conditional adversarial network는 image-to-image translation task에 매우 효과적이다.
특정 task에 맞는 loss를 스스로 adapt하는 개념이기 때문에, 여러 종류의 세팅에서 활용될 수 있으시다!
